
Welcome to CS251! In this module, our main goal is to explain at a high-level what theoretical computer science is about and set the right context for the material covered in the future.
In the first part of the course, we want to build up formally/mathematically, the important notions related to computation and algorithms. We start this journey here by discussing how to formally represent data and how to formally define the concept of a computational problem.

The goal of this module is to introduce you to a simple (and restricted) model of computation known as deterministic finite automata (DFA). This model is interesting to study in its own right, and has very nice applications, however, our main motivation to study this model is to use it as a stepping stone towards formally defining the notion of an algorithm in its full generality. Treating deterministic finite automata as a warm-up, we would like you to get comfortable with how one formally defines a model of computation, and then proves interesting theorems related to the model. Along the way, you will start getting comfortable with using a bit more sophisticated mathematical notation than you might be used to. You will see how mathematical notation helps us express ideas and concepts accurately, succinctly and clearly.

In this module, our main goal is to introduce the definition of a Turing machine, which is the standard mathematical model for any kind of computational device. As such, this definition is very foundational. As we discuss in lecture, the physical Church-Turing thesis asserts that any kind of physical device or phenomenon, when viewed as a computational process mapping input data to output data, can be simulated by some Turing machine. Thus, rigorously studying Turing machines does not just give us insights about what our laptops can or cannot do, but also tells us what the universe can and cannot do computationally. This module kicks things off with examples of computable problems. In the next module, we will start exploring the limitations of computation.

In this module, we prove that most problems are undecidable, and give some explicit examples of undecidable problems. The two key techniques we use are diagonalization and reductions. These are two of the most fundamental concepts in mathematics and computer science.

The late 19th to early 20th century was an important time in mathematics. With various problems arising with the usual way of doing mathematics and proving things, it became clear that there was a need to put mathematical reasoning on a secure foundation. In other words, there was a need to mathematically formalize mathematical reasoning itself. As mathematicians took on the task of formalizing mathematics, two things started to become clear. First, a complete formalization of mathematics was not going to be possible. Second, formalization of mathematics involves formalizing what we informally understand as “algorithm” or “computation”. This is because one of the defining features of mathematical reasoning is that it is a computation. In this module we will make this connection explicit and see how the language of theoretical computer science can be effectively used to answer important questions in the foundations of mathematics.

So far, we have formally defined what a computational/decision problem is, what an algorithm is, and saw that most (decision) problems are undecidable. We also saw some explicit and interesting examples of undecidable problems. Nevertheless, it turns out that many problems that we care about are actually decidable. So the next natural thing to study is the computational complexity of problems. If a problem is decidable, but the most efficient algorithm solving it takes vigintillion computational steps even for reasonably sized inputs, then practically speaking, that problem is still undecidable. In a sense, computational complexity is the study of practical computability.
Even though computational complexity can be with respect to various resources like time, memory, randomness, and so on, we will be focusing on arguably the most important one: time complexity. In this module, we will set the right context and language to study time complexity.
In the study of computational complexity of languages and computational problems, graphs play a very fundamental role. This is because an enormous number of computational problems that arise in computer science can be abstracted away as problems on graphs, which model pairwise relations between objects. This is great for various reasons. For one, this kind of abstraction removes unnecessary distractions about the problem and allows us to focus on its essence. Second, there is a huge literature on graph theory, so we can use this arsenal to better understand the computational complexity of graph problems. Applications of graphs are too many and diverse to list here, but we’ll name a few to give you an idea: communication networks, finding shortest routes in various settings, finding matchings between two sets of objects, social network analysis, kidney exchange protocols, linguistics, topology of atoms, and compiler optimization.
This module introduces basic graph theoretic concepts as well as some of the fundamental graph algorithms.
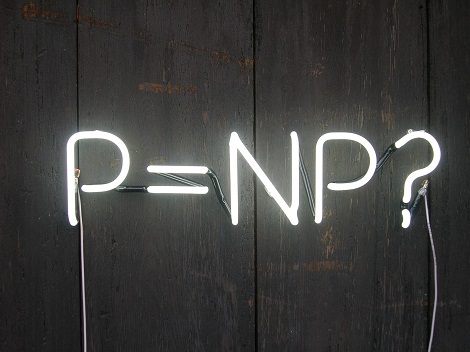
In this module, we introduce the complexity class NP and discuss the most important open problem in computer science: the P vs NP problem. The class NP contains many natural and well-studied languages that we would love to decide in polynomial time. In particular, if we could decide the languages in NP efficiently, this would lead to amazing applications. For instance, in mathematics, proofs to theorems with reasonable length proofs would be found automatically by computers. In artificial intelligence, many machine learning tasks we struggle with would be easy to solve (like vision recognition, speech recognition, language translation and comprehension, etc). Many optimization tasks would become efficiently solvable, which would affect the economy in a major way. Another main impact would happen in privacy and security. We would say “bye” to public-key cryptography which is being used heavily on the internet today. (We will learn about public-key cryptography in a later module.) These are just a few examples; there are many more.
Our goal in this module is to present the formal definition of NP, and discuss how it relates to P. We also discuss the notion of NP-completeness (which is intimately related to the question of whether NP equals P) and give several examples of NP-complete languages.

Randomness is an essential concept and tool in modeling and analyzing nature. Therefore, it should not be surprising that it also plays a foundational role in computer science. For many problems, solutions that make use of randomness are the simplest, most efficient and most elegant solutions. And in many settings, one can prove that randomness is absolutely required to achieve a solution. (We mention some concrete examples in lecture.)
One of the primary applications of randomness to computer science is randomized algorithms. A randomized algorithm is an algorithm that has access to a randomness source like a random number generator, and a randomized algorithm is allowed to err with a very small probability of error. There are computational problems that we know how to solve efficiently using a randomized algorithms, however, we do not know how to solve those problems efficiently with a deterministic algorithm (i.e. an algorithm that does not make use of randomness). In fact, one of the most important open problems in computer science asks whether every efficient randomized algorithm has a deterministic counterpart solving the same problem. In this module, we start by reviewing probability theory, and then introduce the concept of randomized algorithms.

The quest for secure communication in the presence of adversaries is an ancient one. From Caesar shift to the sophisticated Enigma machines used by Germans during World War 2, there have been a variety of interesting cryptographic protocols used in history. But it wasn’t until the computer science revolution in the mid 20th century when the field of cryptography really started to flourish. In fact, it is fair to say that the study of computational complexity completely revolutionized cryptography. The key idea is to observe that any adversary would be computationally bounded just like anyone else. And we can exploit the computational hardness of certain problems to design beautiful cryptographic protocols for many different tasks. In this module, we will first review the mathematical background needed (modular arithmetic), and then present some of the fundamental cryptographic protocols to achieve secure communication.

In this module, we present a selection of highlights from theoretical computer science.